Pandas는 데이터 분석을 위한 파이썬 라이브러리입니다. SQL은 관계형 데이터베이스를 처리하는데 사용되는 프로그래밍 언어입니다. 공통점은 Pandas와 SQL이 모두 테이블 형식 데이터(즉, 테이블이 행과 열로 구성됨)에서 작동한다는 것입니다.
Pandas와 SQL은 모두 테이블 형식 데이터를 처리하므로 둘 중 하나를 사용하여 유사한 작업 또는 쿼리 업무를 수행 할 수 있습니다. 이번 포스팅에서는 Pandas 구문으로 SQL 쿼리를 다시 작성해 보겠습니다. 따라서 두 가지 모두를 위한 실용적인 가이드가 될 것입니다.
15개의 행과 4개의 열로 구성되어 있는 SQL 테이블과 Pandas 데이터 프레임이 있습니다. 처음 5개 행을 표시해 보겠습니다.
mysql> select * from items limit 5;
+---------+--------------+-------+----------+
| item_id | description | price | store_id |
+---------+--------------+-------+----------+
| 1 | apple | 2.45 | 1 |
| 2 | banana | 3.45 | 1 |
| 3 | cereal | 4.20 | 2 |
| 4 | milk 1 liter | 3.80 | 2 |
| 5 | lettuce | 1.80 | 1 |
+---------+--------------+-------+----------+
여러 소매점에서 판매되는 상품 목록에 대한 데이터가 있습니다. 다음 예제에서는 SQL 쿼리 작업을 작성하고 Pandas에서도 동일한 작업을 수행해 보겠습니다.
예제 1
작업내용: 각 상점의 평균 품목 가격 구하기
상점 ID 열을 기준으로 가격을 그룹화하고 각 상점의 평균 값을 계산해야 합니다.
mysql> select avg(price), store_id
-> from items
-> group by store_id;
+------------+----------+
| avg(price) | store_id |
+------------+----------+
| 1.833333 | 1 |
| 3.820000 | 2 |
| 3.650000 | 3 |
+------------+----------+SQL에서는 select과 함께 집계 함수 (avg)를 적용합니다. group by 절은 상점 ID 열의 카테고리를 기반으로 가격을 그룹화합니다.
items[['price', 'store_id']].groupby('store_id').mean()
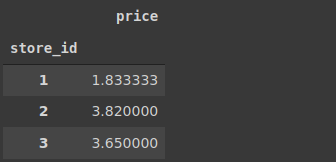
Pandas에서는 groupby 함수를 먼저 사용한 후에 집계를 적용합니다.
예시 2
작업내용: 가격 열의 이름을 "average_price"로 바꾸고 평균 가격을 기준으로 상점을 정렬하여 이전 예제의 결과를 수정하십시오.
SQL에서는 이름 바꾸기에 AS 키워드를 사용하고 결과를 정렬하기 위해 끝에 order by 절을 추가합니다.
mysql> select store_id, avg(price) as average_price
-> from items
-> group by store_id
-> order by average_price;
+----------+---------------+
| store_id | average_price |
+----------+---------------+
| 1 | 1.833333 |
| 3 | 3.650000 |
| 2 | 3.820000 |
+----------+---------------+Pandas에는 가격 열의 이름을 변경하는데 사용할 수 있는 옵션이 여러개 있습니다. 이번에는 agg 메서드를 사용할 것입니다. 결과를 정력하기 위해서 sort_values 함수를 사용합니다.
items[['price', 'store_id']].groupby('store_id')\
.agg(average_price = pd.NamedAgg('price','mean'))\
.sort_values(by='average_price')
예제 3
작업내용: 상점 ID가 3 인 모든 항목을 찾습니다.
상점 ID 열을 기준으로 행을 필터링하면 됩니다. SQL에서는 where 절을 사용하여 수행됩니다.
mysql> select * from items
-> where store_id = 3;
+---------+----------------+-------+----------+
| item_id | description | price | store_id |
+---------+----------------+-------+----------+
| 7 | water 2 liters | 1.10 | 3 |
| 9 | egg 15 | 4.40 | 3 |
| 10 | sprite 1 liter | 1.60 | 3 |
| 11 | egg 30 | 7.50 | 3 |
+---------+----------------+-------+----------+또한 Pandas에서 매우 간단한 작업입니다.
items[items.store_id == 3]
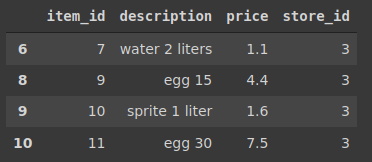
예제 4
작업내용 : 각 상점에서 판매되는 품목 중 가장 아이템 찾기.
이 작업에는 그룹별 집계 과정입니다. SQL에서 max 함수는 price 열에 적용하고, 값은 상점 ID별로 그룹화합니다.
mysql> select description, max(price), store_id
-> from items
-> group by store_id;
+----------------+------------+----------+
| description | max(price) | store_id |
+----------------+------------+----------+
| apple | 3.45 | 1 |
| cereal | 6.10 | 2 |
| water 2 liters | 7.50 | 3 |
+----------------+------------+----------+Pandas에서는 선택한 열을 상점 ID별로 그룹화한 후에 max 함수를 적용합니다.
items[['description','price','store_id']].groupby('store_id').max()
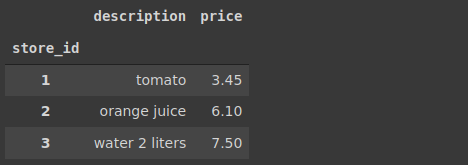
예제 5
작업 내용: '달걀'이라는 단어가 포함 된 모든 항목을 찾습니다.
이 작업에는 필터링이 포함되어 있으며, 위의 예제에서 수행했던 작업과 다릅니다. SQL에서는 where 절과 함께 like 키워드를 사용합니다.
mysql> select * from items
-> where description like '%egg%';
+---------+-------------+-------+----------+
| item_id | description | price | store_id |
+---------+-------------+-------+----------+
| 9 | egg 15 | 4.40 | 3 |
| 11 | egg 30 | 7.50 | 3 |
+---------+-------------+-------+----------+'%egg%' 표기법은 'egg'라는 단어를 포함하는 모든 문자열을 필터링 하겠다는 의미 입니다.
Pandas에서는 str 접근자의 contains 함수를 사용합니다.
items[items.description.str.contains('egg')]
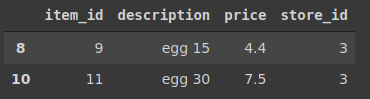
예제 6
작업내용: description 컬럼에 "liter"라는 단어가 포함되어 있고 2달러보다 더 비싼 모든 항목을 찾습니다.
하나의 추가 조건이 있는 이전 예제의 작업과 유사합니다. SQL에서는 where 절에 여러 조건을 배치 할 수 있습니다.
mysql> select * from items
-> where description like '%liter%' and price > 2;
+---------+--------------+-------+----------+
| item_id | description | price | store_id |
+---------+--------------+-------+----------+
| 4 | milk 1 liter | 3.80 | 2 |
+---------+--------------+-------+----------+Pandas에서는 아래와 같이 여러 필터링 조건을 적용 할 수 있습니다.
items[(items.description.str.contains('liter')) & (items.price > 2)]
item_id description price store_id
3 4 milk 1 liter 3.8 2예제 7
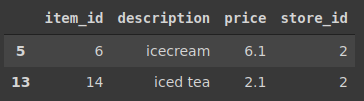
작업내용: description 컬럼이 'ice'로 시작하는 모든 항목을 찾습니다.
이것은 또 다른 텍스트 기반 필터링입니다. SQL에서 like 연산자 또는 left 함수를 사용하여 설명의 처음 세 문자를 'ice'와 비교할 수 있습니다.
mysql> select * from items
-> where left(description, 3) = 'ice';
+---------+-------------+-------+----------+
| item_id | description | price | store_id |
+---------+-------------+-------+----------+
| 6 | icecream | 6.10 | 2 |
| 14 | iced tea | 2.10 | 2 |
+---------+-------------+-------+----------+
mysql> select * from items where description like 'ice%';
+---------+-------------+-------+----------+
| item_id | description | price | store_id |
+---------+-------------+-------+----------+
| 6 | icecream | 6.10 | 2 |
| 14 | iced tea | 2.10 | 2 |
+---------+-------------+-------+----------+Pandas에서는 str 접근 자의 startswith 함수를 사용할 수 있습니다.
items[items.description.str.startswith('ice')]
결론
Pandas와 SQL은 모두 데이터 사이언스 분야에서 많이 사용되는 도구입니다. 데이터 사이언스 분야에서 일하고 있거나 일할 계획이라면 둘 다 배우는 것이 좋습니다.
Pandas와 SQL을 모두 사용하여 데이터를 검색하기 위해 몇 가지 기본 쿼리를 수행했습니다. 동일한 작업을 수행하여 비교함으로써 하나의 언어에서 다른 언어로 확장하려는 분들의 이해를 높이고자 했습니다.
참고) 이번 포스팅의 원문을 아래 링크를 통해서 읽어보실 수 있습니다.
https://towardsdatascience.com/rewriting-sql-queries-with-pandas-ac08d9f054ec
Rewriting SQL Queries with Pandas
Practical guide for both SQL and Pandas
towardsdatascience.com
'데이터과학 > 데이터 분석 실습' 카테고리의 다른 글
| AWS SageMaker를 이용해서 모델 빌드, 배포, 예측하기 (1) | 2021.01.19 |
|---|---|
| Prophet을 이용한 주가 예측 (0) | 2021.01.04 |
| 실제 강도 지수를 이용한 알고리즘 트레이딩 (feat. 파이썬) (0) | 2020.12.31 |
| 스토캐스틱 지표를 이용한 알고리즘 투자전략 (feat. 파이썬) (0) | 2020.12.30 |
| 시계열 안정성 테스트 - ADF and KPSS 테스트 (feat. 파이썬) (5) | 2020.12.25 |



